1. 简介
语音识别技术(Automatic Speech Recognition)简称 ASR,是一种将人的语音转换为文本的技术。语音识别是一个多学科交叉的领域,它与声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科紧密相连。语音识别技术的应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用,例如语音到语音的翻译 语音识别技术(Automatic Speech Recognition)简称 ASR,是一种将人的语音转换为文本的技术。语音识别是一个多学科交叉的领域,它与声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科紧密相连。语音识别技术的应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用,例如语音到语音的翻译
灵云语音识别为开发者提供业界优质的语音服务,通过场景识别优化,为车载导航,智能家居和社交聊天等行业提供语音解决方案,准确率达到 90% 以上,让您的应用绘“声”绘色。语音识别客户端 SDK 是一种面向多平台的解决方案,开发者可根据需要进行相应选择。指南中定义了语法识别、自由说识别、意图识别、实时识别、实时反馈、双路识别等服务接口的使用。
本文档旨在让开发者快速集成 ASR 能力 SDK,如在集成过程中如有疑问,可登录灵云开发者论坛,查找答案或与其他开发者交流。
1.1 概念解释
为了更好地理解后续的内容,这里对文档中出现的若干专有名词进行解释说明。
- 根据应用场景的不同,捷通华声将ASR主要分为两类:语法识别和自由说识别,分别提供本地识别和云端识别两种调用模式
本地识别:
本地识别即离线识别模式,加载本地模型并调用本地识别引擎进行语音识别工作,使用的本地设备的计算能力。
云端识别:
云端识别即在线识别模式,调用云端引擎进行语音识别工作,使用的是云端服务的计算能力。
语法识别:
语法识别是指待识别的内容满足一定的规则,系统在语法文件(开发者提供)指定的规则范围内进行识别。有限命令词汇的识别我们也归为语法识别,可将这些命令词的集合看作是一种特殊的语法。常用于命令操作、简单的意图控制等。
自由说识别:
自由说识别则不限定用户说话的范围、方式和内容。但在实际使用时,一般会根据讲话内容的领域采用相应的语言模型作为支撑,以便获得更好的识别率。常用于输入短信、微博或比较随意的对话系统等。
- 根据识别过程的实时性,还可以分为非流式识别,实时识别和实时反馈
非流式识别:
非流式识别即非实时识别,音频数据在整体输入之后才会被进行识别,与实时识别相比响应速度会慢一些。一般用于识别音频数据文件。
实时识别:
实时识别则可以实现边录音边识别,用户可以将音频数据分段多次传入,在输入音频结束后返回最终的识别结果,这样能够获得更快的响应速度。
实时反馈:
实时反馈则在实时识别的基础上进一步优化用户体验,识别的中间过程中也可以反馈识别结果,并可以随着语音数据的增多,根据语境对已反馈的识别结果进行修正。
1.2 能力定义(capkey)
ASR 支持多种能力,通过 capkey 区分不同能力的调用和配置。其中常用 capkey 如下所示:
| capkey | 说明 | 领域 | 所需资源文件 |
|---|---|---|---|
| asr.local.freetalk | 本地自由说 | model_carnav_common 通用模型 model_carnav_poi 导航模型 |
ft_decoder.conf ispk_dnn.dat ispk_hclg.dat ispk_blm.dat ispk_slm.dat |
| asr.local.grammar.v4 | 本地语法识别 | model_carnav_common 通用模型 | grm_decoder.conf ispk_aux.dat ispk_dnn.dat ispk_g2p.dat |
| asr.cloud.freetalk | 通用领域自由说-中文 | common, music, poi,... | |
| asr.cloud.grammar | 语法识别-中文 | common | |
| asr.cloud.dialog | 语音意图理解-中文 | common | |
| asr.cloud.freetalk.english | 通用领域自由说-英文 | common | |
| asr.cloud.freetalk.uyghur | 通用领域自由说-维吾尔语 | common | |
| asr.cloud.freetalk.taiwan | 通用领域自由说-台湾国语 | common | |
| asr.cloud.freetalk.cantonese | 通用领域自由说-粤语 | common | |
| asr.cloud.freetalk.kazak | 通用领域自由说-哈萨克语 | common | |
| asr.cloud.freetalk.utsang | 通用领域自由说-藏语 | common | |
| asr.cloud.freetalk.korean | 通用领域自由说-朝鲜语 | common | |
| asr.cloud.freetalk.yi | 通用领域自由说-彝语 | common | |
| asr.cloud.freetalk.mongolian | 通用领域自由说-蒙文 | common | |
| asr.cloud.freetalk.amdo | 通用领域自由说-藏语安多 | common | |
| asr.cloud.freetalk.kham | 通用领域自由说-藏语康巴 | common | |
| asr.cloud.freetalk.yangjiang | 通用领域自由说-广东阳江话 | common |
1.2.1 识别领域
能力定义的表格中,ASR 可以指定识别的领域,针对不同的领域使用其对应的模型进行识别,能够得到更为准确的识别结果。比如asr.cloud.freetalk下,指定领域为poi,对于导航路名的识别效果会很好。
1.2.2 资源文件
能力定义的表格中,本地能力需要加载的模型数据文件。不同的领域,需要不同的资源文件。
1.3 语法介绍
ASR 语法识别支持多种语法类型,其中包括jsgf,wordlist,wfst。
- JSGF(Java Speetch Grammar Format)是 W3C 制定的标准语法格式,可以参考JSGF规范。JSGF语法示例
#JSGF V1.0 grammar call; public <call> = 打电话给 <contactname>; <contactname> = ( 张三 | 李四 ); - wordlist 词条语法。wordlist 语法示例
播放 暂停 停止 上一首 下一首 - wfst
语法识别支持支持在语法文件中设置权重,权重可以是任意浮点数,后面不带数字,缺省值为 1。
JSGF语法文件权重示例
<size> = /10/ small | /2/ medium | /1/ large;
<action> = please (/20/save files |/1/delete all files);
<place> = /20/ <city> | /5/ <country>;
wordlist 语法文件权重示例
四川长虹 /2/
山西电力 /0.5/
1.4 调用流程
主要功能接口的调用过程,如下图所示
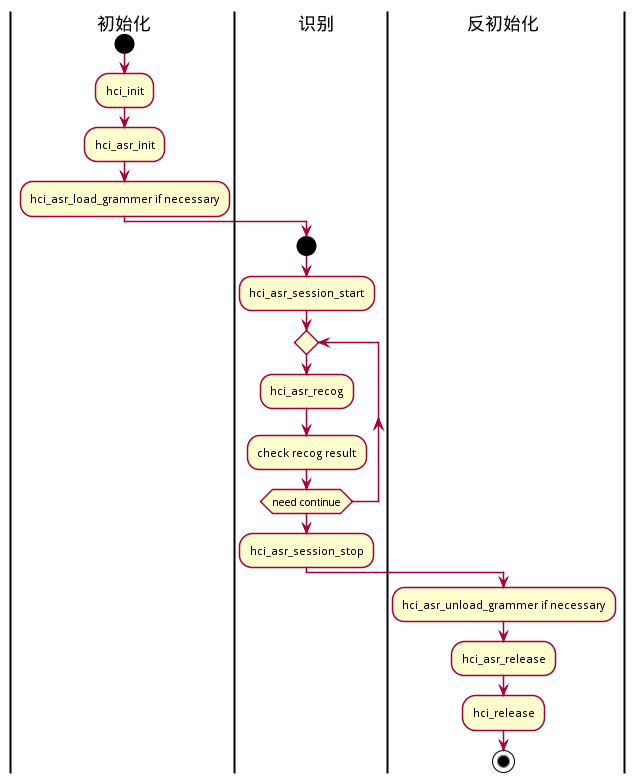
2. ASR能力使用说明
2.1 创建应用
在集成 ASR 之前,开发者需要在灵云开发者社区创建相关应用,并保存appkey,developerkey等信息。
2.2 导入SDK
2.2.1 使用 Android 版SDK
2.2.1.1 下载SDK
下载语音识别SDK并解压缩。

2.2.1.2 导入库
解压SDK 目录:
sdk\Examples\ASR_Example\app\libs\hcicloud-8.1.jar为便于访问引擎的sdk包,可放置在您的项目的libs目录下;sdk\Examples\ASR_Example\app\src\main\jniLibs文件夹中包含 ASR 能力所需要armeabi,armeabi-v7a,arm64-v8a等相应平台的库,开发者可以根据集成需要进行选择需要的动态库放到您的项目的jniLibs下。sdk\Examples\ASR_Example\app\src\main\assets\data目录下预置了 本地语法识别与本地自由说识别使用的资源文件。sdk\Examples\ASR_Example\app\src\main\assets\AccountInfo.txt文件是样例工程获取账号的配置文件,开发者填写可用账号与合适的capkey,即可编译运行,进行识别。
2.2.1.3 ABI介绍
开发者可以根据自身需求组合所需要的ABI库。
必选模块
- hcicloud-8.1.jar
- libhci_sys.so
- libhci_sys_jni.so
- libhci_curl.so
- libhci_asr_jni.so
- libhci_asr.so
云端识别
- libhci_asr_cloud_recog.so
- libjtspeex.so
- libjtopus.so
本地语法识别
- libhci_asr_local_recog.so
- libiSpeakGrmDNNLite.so
本地自由说识别
- libhci_asr_local_ft_recog.so
- libiSpeakDNNLite.so
特别注意
Module的build.gradle中,必须配置packagingOptions.doNotStrip参数,以保留灵云SDK中的签名信息,该信息在SDK内部使用,用来保护灵云SDK的知识版权。 若此参数未配置,或配置不正确,在进行本地能力调用时,将会返回本地引擎初始化失败的信息。
build.gradle示例
apply plugin: 'com.android.application' android { compileSdkVersion 17 buildToolsVersion "27.0.3" defaultConfig { applicationId "com.sinovoice.example" minSdkVersion 7 targetSdkVersion 17 packagingOptions { doNotStrip "*/armeabi/*.so" doNotStrip "*/armeabi-v7a/*.so" doNotStrip "*/arm64-v8a/*.so" // add other if needed } } buildTypes { release { minifyEnabled false proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.txt' } } } dependencies { compile files('libs/hcicloud-8.1.jar') compile files('libs/hcicloud_recorder-8.1.jar') }
2.2.1.4 添加用户权限
在工程 AndroidManifest.xml 文件中添加如下权限。
<!—通常需要设置一些sd卡路径(例如日志路径)为可写,因此需要能够写外部存储 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
<!—以下访问网络的权限均需要打开-->
<!--连接网络权限,用于执行云端能力 -->
<uses-permission android:name="android.permission.INTERNET" />
<!--获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 -->
<uses-permission android:name="android.permission.RECORD_AUDIO"/>
<!--读取网络信息状态 -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<!--获取当前wifi状态 -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE" />
<!--允许程序改变网络连接状态 -->
<uses-permission android:name="android.permission.CHANGE_NETWORK_STATE" />
<!--读取手机信息权限 -->
<uses-permission android:name="android.permission.READ_PHONE_STATE"/>
<!—以下访问权限可选-->
<!--手机定位信息-->
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION"/>
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION"/>
2.3 导入资源文件
开发者若需调用本地识别能力,则必须将其依赖的资源文件导入工程中。
本地语法模型现提供两种
- model_carnav_common 通用模型
- model_carnav_embeded 车载模型
本地自由说模型现提供三种
- model_carnav_common 通用模型
- model_carnav_embeded 车载模型
- model_carnav_poi 导航模型
请针对不同场景,自行选择。
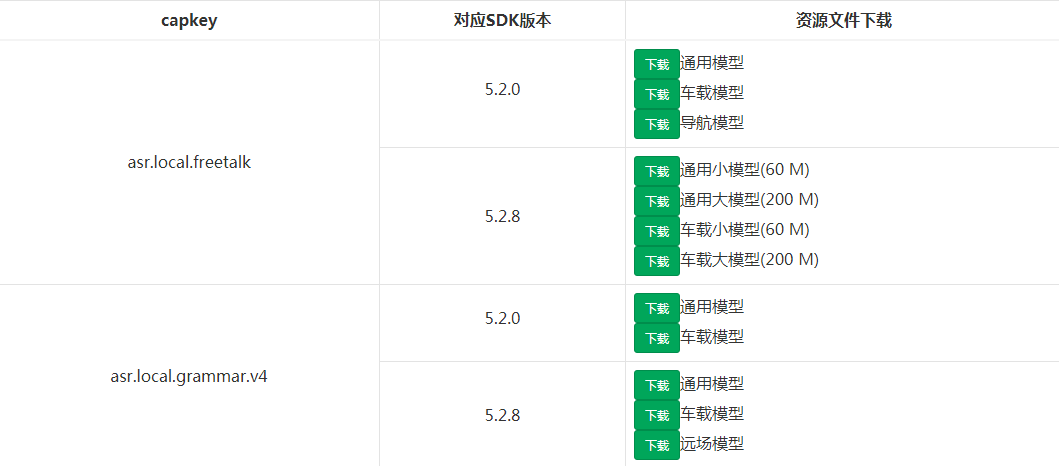
2.3.1 下载资源
如果需要使用本地语法识别,本地自由说识别或本地意图理解时,请下载相应资源包并解压缩。

2.3.2 资源导入
下图为左侧为本地语法识别的通用模型文件,右侧为本地自由说识别的通用小模型(60M)文件
 |
 |
从上面的资源图片可以看到本地语法识别和本地自由说识别所依赖的资源文件,存在同名的情况。如果同时导入工程目录中,会存在冲突问题。为了解决这个问题,灵云SDK中可以配置资源前缀参数resPrefix,详见[语法识别] (#H-4-1)中对此参数的使用。
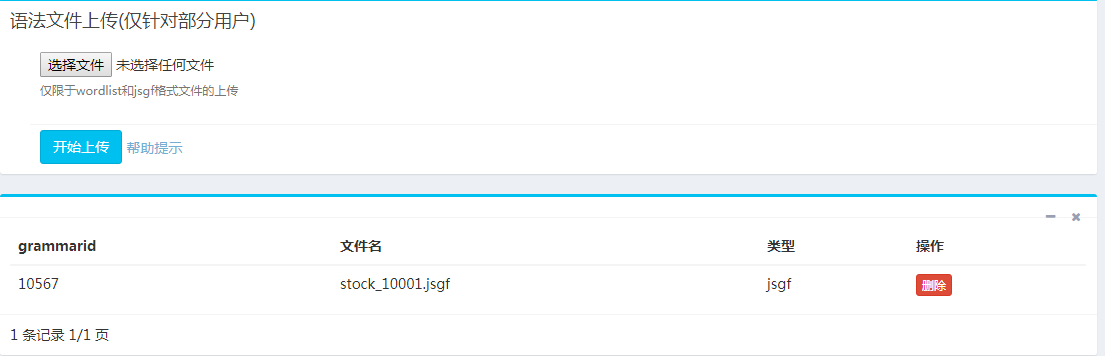
2.4 语法上传
如果是云端语法识别,需要开发者通过开发者社区自行上传语法文件,并获得可以使用的 ID。详情请咨询捷通华声。
3. ASR能力集成
本节主要讲述 ASR 能力的集成过程,开发者可根据本章节内容完成 ASR 能力的简单调用。本章节主要以云端自由说为例讲述 ASR 能力的集成调用流程,调用顺序参考调用流程。其他使用场景的调用,可参见场景分类
3.1 通用模块初始化
在调用ASR能力之前,需要初始化灵云SDK的通用模块。详见灵云SDK开发手册
Android示例代码
// 创建初始化参数辅助类 InitParam initparam = new InitParam(); // 授权文件所在路径,此项必填 String authDirPath = context.getFilesDir() .getAbsolutePath();; initparam.addParam (InitParam.AuthParam.PARAM_KEY_AUTH_PATH, authDirPath) ; // 灵云云服务的接口地址,此项必填 initparam.addParam (InitParam.AuthParam.PARAM_KEY_CLOUD_URL, "http://api.hcicloud.com:8888"); // 开发者密钥,此项必填,由捷通华声提供 initparam.addParam (InitParam.AuthParam.PARAM_KEY_DEVELOPER_KEY, "01234567890"); // 应用程序序号,此项必填,由捷通华声提供 initparam.addParam (InitParam.AuthParam.PARAM_KEY_APP_KEY, "1234abcd"); // 日志的路径,可选,如果不传或者为空则不生成日志 String logDirPath = "/storage/emulated/0/sinovoice/com.sinovoice. example/log"; initparam.addParam (InitParam.LogParam.PARAM_KEY_LOG_FILE_PATH, logDirPath); //日志等级,0=无,1=错误,2=警告,3=信息,4=细节,5=调试 //SDK将输出小于等于logLevel的日志信息 initparam.addParam (InitParam.LogParam.PARAM_KEY_LOG_LEVEL, "5"); // 灵云系统初始化 // 第二个参数在Android平台下,必须为当前的Context int errCode = HciCloudSys.hciInit (initparam.getStringConfig(), this); if(errCode != HciErrorCode.HCI_ERR_NONE) { // "系统初始化失败" return; }
3.2 授权检测
在初始化灵云SDK的通用模块后,还需要调用授权检测函数获取云端授权。
Android示例代码
// 获取授权 private int checkAuthAndUpdateAuth() { // 获取系统授权到期时间 int initResult; AuthExpireTime objExpireTime = new AuthExpireTime (); initResult = HciCloudSys.hciGetAuthExpireTime (objExpireTime); if (initResult == HciErrorCode.HCI_ERR_NONE) { // 显示授权日期,如用户不需要关注该值,此处代码可忽 略 Date date = new Date (objExpireTime.getExpireTime() * 1000); SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd",Locale.CHINA); Log.i(TAG, "expire time: " + sdf.format(date)) ; if (objExpireTime.getExpireTime() * 1000 > System.currentTimeMillis()) { Log.i(TAG, "checkAuth success"); return initResult; } } // 获取过期时间失败或者已经过期 initResult = HciCloudSys.hciCheckAuth(); if (initResult == HciErrorCode.HCI_ERR_NONE) { Log.i(TAG, "checkAuth success"); return initResult; } else { Log.e(TAG, "checkAuth failed: " + initResult); return initResult; } }
3.3 ASR 初始化
在初始化灵云SDK的SYS通用模块和授权检测成功后,需调用 ASR 初始化函数。
Android代码
// 初始化 int errCode = HciCloudAsr.hciAsrInit(asrInitParam.getStringConfig()); if (errCode != HciErrorCode.HCI_ERR_NONE) { showLogOnUi("HciAsrInit error:" + HciCloudSys.hciGetErrorInfo(errCode)); return; } else { showLogOnUi("HciAsrInit Success"); }
3.4 开启会话(session)
ASR 是通过会话(session)来管理识别过程的。在ASR能力初始化成功之后,需要通过开启识别会话来完成识别。
Android代码
// 启动Session AsrConfig sessionConfig = new AsrConfig(); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_CAP_KEY, "asr.cloud.freetalk"); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_REALTIME, AsrConfig.VALUE_OF_YES); Session nSessionId = new Session(); errCode = HciCloudAsr.hciAsrSessionStart(sessionConfig.getStringConfig(), nSessionId); if (HciErrorCode.HCI_ERR_NONE != errCode) { showLogOnUi("hciAsrSessionStart return:" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode)); return; } showLogOnUi("hciAsrSessionStart Success");
3.5 语音识别
在启动会话(session)成功后,即可进行 ASR 识别过程。识别功能通过调用识别函数完成。这里使用默认的识别参数,直接将识别数据传入识别;如果是实时识别或实时反馈,则需要多次调用识别函数将语音数据送入 SDK。
Android代码
// 启动识别 AsrConfig recogConfig = new AsrConfig(); recogConfig.addParam(AsrConfig.AudioConfig.PARAM_KEY_ENCODE, AsrConfig.AudioConfig.VALUE_OF_PARAM_ENCODE_SPEEX); AsrRecogResult asrResult = new AsrRecogResult(); String audioFile = "sinovoice.pcm"; byte[] voiceData = HciCloudHelper.getAssetFileData(audioFile); if (null == voiceData) { showLogOnUi("Open input voice file" + audioFile + " error!"); return; } errCode = HciCloudAsr.hciAsrRecog(nSessionId, voiceData, recogConfig.getStringConfig(), null, asrResult); if (HciErrorCode.HCI_ERR_NONE == errCode) { // 输出识别结果 printAsrResult(asrResult); } else{ showLogOnUi("hciAsrRecog return:" + errCode + " "+ HciCloudSys.hciGetErrorInfo(errCode)); } // 输出识别结果的方法 private void printAsrResult(AsrRecogResult recogResult) { if (recogResult.getRecogItemList().size() < 1) { showLogOnUi("recognize result is null"); } for (int i = 0; i < recogResult.getRecogItemList().size(); i++) { if (recogResult.getRecogItemList().get(i).getRecogResult() != null) { String utf8 = recogResult.getRecogItemList().get(i) .getRecogResult(); showLogOnUi("result index:" + String.valueOf(i) + " result:" + utf8); } else { showLogOnUi("result index:" + String.valueOf(i) + " result: null"); } } }
3.6 结束识别
最后我们需要反初始化,依次关闭会话,终止 ASR 能力,关闭灵云系统。
Android代码
// 终止session HciCloudAsr.hciAsrSessionStop(nSessionId); //反初始化ASR HciCloudAsr.hciAsrRelease(); //ShowMessage("hciAsrRelease"); HciCloudSys.hciRelease();
4. 场景分类
根据不同的使用场景划分为语法识别和自由说识别,同时还可以根据实时性分为非流式识别,实时识别和实时反馈。
按识别能力分:
| 场景 | 说明 |
|---|---|
| 语法识别 | 简单的语音控制命令,占资源少 |
| 自由说识别 | 不限定语音内容,自由识别 |
按识别的方式:
| 场景 | 说明 |
|---|---|
| 非流式识别 | 用于较短离线数据的识别,调用方式简单 |
| 实时识别 | 用于一边录音,一边识别的场景 |
| 实时反馈 | 用于一边录音,一边识别的场景,但结果会实时反馈给调用者 |
识别能力下,识别方式的支持情况:
| 支持情况 | 语法识别 | 自由说识别 |
|---|---|---|
| 非流式识别 | 支持 | 支持 |
| 实时识别 | 支持 | 支持 |
| 实时反馈 | 不支持 | 仅云端自由说支持 |
4.1 语法识别
语法识别可以分为本地语法识别(asr.local.grammar.v4)和云端语法识别(asr.cloud.grammar)。系统根据开发者提供的语法文件在指定的语法范围内进行识别。这种识别计算资源消耗少,识别率较高,但是要求用户的说话内容必须符合指定的语法。
Android代码
使用语法识别需要导入相应的库,详见2.2.1.2 ABI介绍
// 加载本地语法 AsrGrammarId grammarId = new AsrGrammarId(); AsrConfig loadGrammarConfig = new AsrConfig(); loadGrammarConfig.addParam(AsrConfig.GrammarConfig.PARAM_KEY_GRAMMAR_TYPE, AsrConfig.GrammarConfig.VALUE_OF_PARAM_GRAMMAR_TYPE_JSGF); loadGrammarConfig.addParam(AsrConfig.GrammarConfig.PARAM_KEY_IS_FILE, AsrConfig.VALUE_OF_NO); //由于DATAPATH下有多种模型,需通过资源前缀参数指定具体的本地资源文件 loadGrammarConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_RES_PREFIX, "grammar_"); // 必须传入capkey loadGrammarConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_CAP_KEY, "asr.local.grammar.v4"); byte[] grammarData = HciCloudHelper.getAssetFileData("stock_10001.gram"); String strGrammarData = null; try { strGrammarData = new String(grammarData, "utf-8"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } errCode = HciCloudAsr.hciAsrLoadGrammar(loadGrammarConfig.getStringConfig(), strGrammarData, grammarId); if (errCode != HciErrorCode.HCI_ERR_NONE) { showLogOnUi("hciAsrLoadGrammar return:" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode)); HciCloudAsr.hciAsrRelease(); return; } else { showLogOnUi("hciAsrLoadGrammar Success"); }启动识别会话:
// 启动Session AsrConfig sessionConfig = new AsrConfig(); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_CAP_KEY, "asr.local.grammar.v4"); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_REALTIME, "no"); sessionConfig.addParam(AsrConfig.GrammarConfig.PARAM_KEY_GRAMMAR_TYPE, AsrConfig.GrammarConfig.VALUE_OF_PARAM_GRAMMAR_TYPE_ID); sessionConfig.addParam(AsrConfig.GrammarConfig.PARAM_KEY_GRAMMAR_ID, grammarId.toString()); // 由于DATAPATH下有多种模型,需通过资源前缀参数指定具体的本地资源文件 sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_RES_PREFIX, "grammar_"); Session nSessionId = new Session(); errCode = HciCloudAsr.hciAsrSessionStart(sessionConfig.getStringConfig(), nSessionId); if (HciErrorCode.HCI_ERR_NONE != errCode) { showLogOnUi("hciAsrSessionStart return:" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode)); return; } showLogOnUi("hciAsrSessionStart Success");
启动识别:
// 启动识别
AsrConfig recogConfig = new AsrConfig();
recogConfig.addParam(AsrConfig.AudioConfig.PARAM_KEY_ENCODE, AsrConfig.AudioConfig.VALUE_OF_PARAM_ENCODE_SPEEX);
AsrRecogResult asrResult = new AsrRecogResult();
String audioFile = "sinovoice.pcm";
byte[] voiceData = HciCloudHelper.getAssetFileData(audioFile);
if (null == voiceData) {
showLogOnUi("Open input voice file" + audioFile + " error!");
return;
}
errCode = HciCloudAsr.hciAsrRecog(nSessionId, voiceData, recogConfig.getStringConfig(), null, asrResult);
if (HciErrorCode.HCI_ERR_NONE == errCode) {
// 输出识别结果
printAsrResult(asrResult);
}
else{
showLogOnUi("hciAsrRecog return:" + errCode + " "+ HciCloudSys.hciGetErrorInfo(errCode));
}
卸载语法,终止Session,释放资源:
// 卸载模板
errCode = HciCloudAsr.hciAsrUnloadGrammar(grammarId);
showLogOnUi("hciAsrUnloadGrammar return :" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode));
// 终止Session
errCode = HciCloudAsr.hciAsrSessionStop(nSessionId);
showLogOnUi("hciAsrSessionStop return :" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode));
// 释放
errCode = HciCloudAsr.hciAsrRelease();
showLogOnUi("hciAsrRelease return :" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode));
4.2 自由说识别
自由说识别分为本地自由说识别(asr.local.freetalk)和云端自由说识别(asr.cloud.freetalk)。不限定用户说话的范围、方式和内容。自由说识别常常需要较大的语言模型作为支撑,因此消耗计算资源较大。但这种识别可以用于输入短信、微博或比较随意的对话系统等。针对某些特定领域,也可以采用针对这一领域的语言模型作为支撑,因此对于说话集中在这个领域的内容会获得更好的识别率。例如可以针对歌曲歌手的名称专门建立“音乐”领域的自由说模型。
以云端自由说识别为例:
Android代码
// 启动Session AsrConfig sessionConfig = new AsrConfig(); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_CAP_KEY, "asr.cloud.freetalk"); Session nSessionId = new Session(); errCode = HciCloudAsr.hciAsrSessionStart(sessionConfig.getStringConfig(), nSessionId); if (HciErrorCode.HCI_ERR_NONE != errCode) { showLogOnUi("hciAsrSessionStart return:" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode)); return; } showLogOnUi("hciAsrSessionStart Success"); // 启动识别 AsrConfig recogConfig = new AsrConfig(); recogConfig.addParam(AsrConfig.AudioConfig.PARAM_KEY_ENCODE, AsrConfig.AudioConfig.VALUE_OF_PARAM_ENCODE_SPEEX); AsrRecogResult asrResult = new AsrRecogResult(); String audioFile = "sinovoice.pcm"; byte[] voiceData = HciCloudHelper.getAssetFileData(audioFile); if (null == voiceData) { showLogOnUi("Open input voice file" + audioFile + " error!"); return; } errCode = HciCloudAsr.hciAsrRecog(nSessionId, voiceData, recogConfig.getStringConfig(), null, asrResult); if (HciErrorCode.HCI_ERR_NONE == errCode) { // 输出识别结果 printAsrResult(asrResult); } else{ showLogOnUi("hciAsrRecog return:" + errCode + " "+ HciCloudSys.hciGetErrorInfo(errCode)); }
4.3 实时识别
主要用于一边录音,一边识别的场景。启动会话时可通过设置 realtime=yes 来启用实时识别模式,之后可以持续调用识别方法传入语音数据。在识别过程中,返回以下情况:
- HCI_ERR_ASR_REALTIME_WAITNG,表示未检测到语音活动结束,需要继续传入语音数据;
- HCI_ERR_ASR_REALTIME_END,表示检测到语音活动结束或者缓冲区满,此时需要调用识别方法传入 NULL 来获取识别结果;
- HCI_ERR_ASR_REALTIME_NO_VOICE_INPUT, 表示没有检测到前端点,超过了vadHead范围
Android代码
// 启动Session AsrConfig sessionConfig = new AsrConfig(); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_CAP_KEY, "asr.cloud.freetalk"); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_REALTIME, AsrConfig.VALUE_OF_YES); Session nSessionId = new Session(); errCode = HciCloudAsr.hciAsrSessionStart(sessionConfig.getStringConfig(), nSessionId); if (HciErrorCode.HCI_ERR_NONE != errCode) { showLogOnUi("hciAsrSessionStart return:" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode)); return; } showLogOnUi("hciAsrSessionStart Success"); // 启动识别 AsrConfig recogConfig = new AsrConfig(); recogConfig.addParam(AsrConfig.AudioConfig.PARAM_KEY_ENCODE, AsrConfig.AudioConfig.VALUE_OF_PARAM_ENCODE_SPEEX); AsrRecogResult asrResult = new AsrRecogResult(); String audioFile = "sinovoice.pcm"; byte[] voiceData = HciCloudHelper.getAssetFileData(audioFile); if (null == voiceData) { showLogOnUi("Open input voice file" + audioFile + " error!"); return; } // 模拟流式数据,每0.2s的数据识别一次 int nPerLen = 6400; //0.2s int nLen = 0; while (nLen < voiceData.length) { if (voiceData.length - nLen <= nPerLen) { nPerLen = voiceData.length - nLen; } byte[] subVoiceData = new byte[nPerLen]; System.arraycopy(voiceData, nLen, subVoiceData, 0, nPerLen); // 调用识别方法,将音频数据不断地传入引擎 errCode = HciCloudAsr.hciAsrRecog(nSessionId, subVoiceData, null, null, asrResult); if (errCode == HciErrorCode.HCI_ERR_ASR_REALTIME_END) { // 检测到末端点,传入一个 null subVoiceData, sdk将返回识别结果 errCode = HciCloudAsr.hciAsrRecog(nSessionId, null, null, null, asrResult); if (HciErrorCode.HCI_ERR_NONE == errCode) { showLogOnUi("hciAsrRecog Success"); // 输出识别结果 printAsrResult(asrResult); } else{ showLogOnUi("hciAsrRecog error:" + HciCloudSys.hciGetErrorInfo(errCode)); } }else if (errCode == HciErrorCode.HCI_ERR_ASR_REALTIME_WAITING || errCode == HciErrorCode.HCI_ERR_ASR_REALTIME_NO_VOICE_INPUT) { //在连续识别的场景,忽略这两个情况,继续识别后面的音频。 //HCI_ERR_ASR_REALTIME_WAITING (实时识别等待音频)含义是:还没有数据,或者是需要更多数据。 //HCI_ERR_ASR_REALTIME_NO_VOICE_INPUT 含义是:没有检测到音频起点,即超过了vadHead的范围(此时可以让设备进入休眠状态) if(errCode == HciErrorCode.HCI_ERR_ASR_REALTIME_WAITING) { showLogOnUi("hciAsrRecog waiting more data:" + HciCloudSys.hciGetErrorInfo(errCode)); } nLen += nPerLen; } else { // 识别失败 showLogOnUi("hciAsrRecog error:" + HciCloudSys.hciGetErrorInfo(errCode)); break; } try { //模拟真实说话人语速,发送200ms数据后需等待200ms Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } } // 若未检测到端点,但数据已经传入完毕,则需要告诉引擎数据输入完毕 if (errCode == HciErrorCode.HCI_ERR_ASR_REALTIME_END || errCode == HciErrorCode.HCI_ERR_ASR_REALTIME_WAITING) { errCode = HciCloudAsr.hciAsrRecog(nSessionId, null, recogConfig.getStringConfig(), null, asrResult); if (HciErrorCode.HCI_ERR_NONE == errCode) { showLogOnUi("HciCloudAsr hciAsrRecog Success"); // 输出识别结果 printAsrResult(asrResult); } else{ showLogOnUi("hciAsrRecog error:" + HciCloudSys.hciGetErrorInfo(errCode)); } }
4.4 实时反馈
实时反馈即在实时识别的基础上并不只在最后一次获取结果时反馈识别结果,在中间返回过程中也会返回识别结果,此时需要开发者根据返回的识别结果的结构体中的字段进行判断,如果uiResultItemCount > 0则存反馈结果。实时反馈结果不同于实时识别结果,实时反馈结果会分段返回结果。使用方式是在Session配置中指定realtime=rt参数。
Android代码
// 启动Session AsrConfig sessionConfig = new AsrConfig(); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_CAP_KEY, "asr.cloud.freetalk"); sessionConfig.addParam(AsrConfig.SessionConfig.PARAM_KEY_REALTIME, "rt"); Session nSessionId = new Session(); errCode = HciCloudAsr.hciAsrSessionStart(sessionConfig.getStringConfig(), nSessionId); if (HciErrorCode.HCI_ERR_NONE != errCode) { showLogOnUi("hciAsrSessionStart return:" + errCode + " " + HciCloudSys.hciGetErrorInfo(errCode)); return; } showLogOnUi("hciAsrSessionStart Success");
与实时识别直接输出识别结果字符串不同,实时反馈在识别过程中不断返回当前的识别结果。每次获得到识别结果后,需要根据SegmentIndex分段序号来进行分段结果显示,分段序号从1开始,SegmentIndex改变或已经获取到下一个分段则表明前一个分段结果已经完整。
{
"SegmentCount": 1,
"Segment": [{
"SegmentIndex": 1,
"Text": "北京",
"Score": 408,
"StartTime": 0,
"EndTime": 1600
}]
}
{
"SegmentCount": 1,
"Segment": [{
"SegmentIndex": 1,
"Text": "北京捷通华声",
"Score": 2980,
"StartTime": 0,
"EndTime": 1800
}]
}
{
"SegmentCount": 1,
"Segment": [{
"SegmentIndex": 1,
"Text": "北京捷通华声科技",
"Score": 596,
"StartTime": 0,
"EndTime": 2600
}]
}
{
"SegmentCount": 1,
"Segment": [{
"SegmentIndex": 1,
"Text": "北京捷通华声科技股份",
"Score": 1071,
"StartTime": 0,
"EndTime": 3200
}]
}
{
"SegmentCount": 1,
"Segment": [{
"SegmentIndex": 1,
"Text": "北京捷通华声科技股份有限公司",
"Score": 1361,
"StartTime": 0,
"EndTime": 3800
}]
}
Q1: resPrefix 参数有哪些作用?
A: resPrefix 的参数作用是,当调用本地能力时(本地语法,本地自由说或本地意图识别)时,本地识别引擎需要加载一些必要的本地资源文件用于识别。这时当工程目录中需要同时添加多种本地能力时,文件名存在重名状况会出现文件覆盖的情况,这是不被允许的。由于SDK中默认从工程目中读取文件的文件名是固定的,这时可以通过 resPrefix 参数来通知 SDK,需要读取的文件名在原有的基础上需要添加前缀读取,这时多种能力间文件名就解决了冲突问题。
Q2: 我用你们的 ASR 流式识别,java console 控制台一直在打印 211:ASR REALTIME WAITING, 这是个什么错误?
A: 这个不是错误,ASR 流式识别,音频数据块是分片传入的,打印211是说明流式识别还没有检测到末端点,也就是未检测到足够长度的静音,还有音频在传输。
Q3: 你们对每次传入的音频片段长度有什么要求?我调用你们的接口,返回了217号错误:HCI_ERR_ASR_VOICE_DATA_TOO_LARGE?
A: 每次传入的音频片段长度应在(0,32K),否则会返回此错误。SDK流式识别,默认是会对音频做切分的。
Q4: 你们的实时反馈模式,是否支持本地自由说和本地语法能力?
A: realtime=rt,实时反馈识别结果,仅云端自由说asr.cloud.freetalk支持,其它能力均不支持。
Q5: 能否详细说明下端点检测参数vadhead,vadtail,vadthreshold这几个参数的用途?端点检测是否影响识别时间?
A:
- vad head是静音检测头部参数,是指一定时间内没有检测到有效语音就会返no-input-timeout错误,一般设置为10-30s,设置为0代表不检测头部静音超时。vad head不影响识别响应时间。
- vad tail是静音检测尾部参数,实时识别时,识别过程中 检测到连续vad tail时长的静音,认为一句话说完,返回本句的识别结果,一般设置为400-800ms。vad tail会对识别响应时间有影响。
- vad threshold仅影响端点检测灵敏度,越小越灵敏。
Q6: 你们的ASR是否支持speex,opus,amr压缩格式?
A: SDK目前还没有开放对AMR格式的支持,后续会开放。云端如果直接通过http接口调用,是可以传amr格式的音频文件进行识别的。我们支持将音频以speex,opus两种方式进行压缩,默认是以speex格式。但是我们的speex,opus是自定义的jt-speex,jt-opus封包格式,和标准的ogg-speex,ogg-opus封包格式有区别。
Q7: 你们的ASR对于单次输入的音频时长是否有限制?
A: 通过maxseconds参数控制,默认值为30S。如果输入的声音超过此长,非实时识别返回(HCI_ERR_DATA_SIZE_TOO_LARGE)实时识别返回(HCI_ERR_ASR_REALTIME_END)端点检测认为超过maxseconds为缓冲区满。 例外:云端非实时识别由于网速原因,暂时限定不能超过256k。
Q8: 你们对语法文件大小是否有限制?我这边报错:HCI_ERR_ASR_GRAMMAR_DATA_TOO_LARGE?
A: 有限制,语法文件默认的大小范围是(0,64K] 。超出此范围会返回错误。
Q9: 我的需求是实时识别,外接麦克风,说话就出结果,这个你们可以实现吗?
A: android,ios,windows c++版本,都有recorder的示例程序,在我们asr基础接口上,又封装了一层录音机。windows java版本的SDK,目前没有实现对录音机的封装。
Q10: 你们的ASR都支持录入哪些音频格式?
A:
本地识别支持:pcm16k16bit
云端grammar语法识别支持:pcm16k16bit,ulaw16k8bit,alaw16k8bit
云端freetalk和dialog支持:pcm16k16bit,pcm8k16bit,ulaw16k8bit,ulaw8k8bit,alaw16k8bit,alaw8k8bit
注意,实时识别的端点检测暂不支持:alaw, ulaw
Q11: 你们的样例程序包太大了,能裁剪么?
A: 样例程序为了演示不同场景,引入了全部的库文件,以及两组本地资源文件,假如您只使用云端识别,可根据ABI介绍删除不需要的库,本地资源文件也可以去除。